 Figure 1-1
Figure 1-1
This publication is intended to serve as an introduction to some of the concepts embodied in the KeyKOS operating system. KeyKOS, implemented today for IBM 370 architecture computers, addresses the significant computing requirements of today and tomorrow. It provides benefits in the areas of performance, reliability/availability, programmer productivity, and security. The KeyKOS architecture employs the concepts of “capabilities” and “objects” to implement a system which carefully controls all communication between entities.
The entities are called “objects”, and they combine the functions of programs and data.
The “capabilities”, or as they are known in KeyKOS “keys”, explicitly designate the addresses that one object uses to send messages to others. Thus, KeyKOS architecture is a compact wedding of communications, processing, and data. Because KeyKOS architecture hides the details of processors and instruction sets, it is suitable for both centralized and distributed implementations, and for systems with more than one instruction set.
The control that capabilities bring to communication and the modular construction that objects bring to programs and data directly support the design, development, operation, and maintenance of complex systems.
As important as what is provided by the KeyKOS architecture is what is not provided. KeyKOS does not implement many of the policies commonly provided by conventional operating systems. Policies for accounting, auditing, security, information sharing, scheduling, exception handling, naming and referencing files, for example, are not part of KeyKOS. Instead, KeyKOS provides facilities for an application to implement such policies on a case-by-case or system-wide basis.
Many of these types of facilities have already been implemented and are available. This flexibility not only supports today's requirements, but provides for tomorrow's as well.
In a KeyKOS environment, it is possible to implement specific policies for the case at hand. It is therefore possible to emulate other operating system environments and provide bridges between them.
The information presented in this publication is grouped into six chapters:
KeyKOS is a general purpose operating system architecture initially implemented on IBM 370 architecture uniprocessors, such as the IBM 303x, 4300 and compatible computer systems. KeyKOS is designed for implementation on multiprocessors, and can adapt to significant changes of the privileged architecture, such as 370/XA. It is a full function system that supports transaction, interactive, and batch program execution modes.
The KeyKOS architecture provides a conceptually clean division between physical and logical resource management functions. Many logical resource management policies can be simultaneously and independently supported on a single physical resource base.
Unlike other 370 based operating systems, KeyKOS is an object-oriented/capability-based system. Capability-based systems have significant advantages over other systems in the areas of performance, conceptual simplicity, robustness, ease of use, ease of maintenance, and security. Capability-based concepts have been documented in computer science literature for over 15 years, and several prototype systems have been developed as research projects. KeyKOS is the first commercially available implementation of such a system on a mainframe computer. KeyKOS differs from these other systems in that it allows a substantial degree of application program compatibility with existing IBM operating systems. It is a high performance, production oriented system - not a research tool.
To achieve the objectives of performance, conceptual simplicity, robustness, ease of use, maintainability, and security, the following specific design goals were incorporated into KeyKOS:
Capability-based architectures provide a significantly different environment for developing applications and solving programming problems. This difference is most easily understood when contrasted with existing systems.
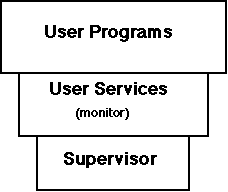
Conventional operating systems are implemented in two or three distinct levels of privilege (some have multiple “rings”, but seldom use many, and a few provide only one level).
Figure 1-1
The lowest level interfaces directly with the hardware and I/O devices, supports multi-programming, and provides services for higher levels. This layer is often called the supervisor. The supervisor generally provides execution environments for the higher levels, which are variously called an address space, job, virtual machine, partition, or virtual memory.
The (optional) second layer runs within a protected part of this execution environment and is often called a monitor. It usually contains facilities such as command language interpreters, access methods, directory support, and debugging tools. Frequently the monitor code is shared between all execution environments, but each environment has its own private working storage.
The third, outermost layer contains all user-level programs, including user written programs, compilers, and many of the system-provided utility functions that do not require the privileges of the lower layers. Note that the three layers exist in a hierarchical relationship.
Strong protection mechanisms provide firewalls between the three layers. Firewalls protect a layer from accidental or intentional harmful acts by programs in the layer above it. However, all programs within a layer run in a common area, with common authority to exercise the privileges of that layer. Common privilege permits the required interactions between a level's components to be executed efficiently.
That same privilege also allows complex implicit and unintended interactions to occur, producing unreliable code, frequently with disastrous consequences. Consider what this could mean in a typical application package:
An application package usually contains several components. For example, mathematical subroutines, an interface to a graphics system, and an interface to a data base management system. All the code supporting these components runs with the same authority.
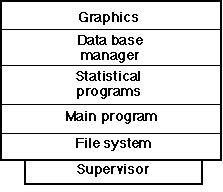 Figure 1-2
Figure 1-2
Since all share the same execution environment, there is no assurance that the code in any one of these components will not destroy or alter data or programs belonging to another component.
In this example, it is possible for any part of the application to access the data buffers of the data base manager (if it can find them). Even if the data base manager carefully cleans up after itself, a security exposure can exist if the application program processes interrupts from external sources, thereby possibly interrupting the data base manager from cleaning up. In addition, a bug in the graphics package can influence the mathematical subroutine package without leaving a clue to the cause. These exposures greatly complicate problem resolution.
This lack of protection exists in each of the three levels of the operating system. In each case, the consequences are propagated throughout the level in which the failure occurs. At the third level, an application program is terminated or produces incorrect results. At the second level, a job or file is compromised. At the first level, the entire computer system can be disabled by a single error.
Reliability, integrity, and security can be attained by partitioning each layer into several, isolated entities which can only communicate through explicit and controlled interfaces. In such an environment the graphics package, for example, could exist in its own execution environment with its code and data completely protected. If it failed, the flaw would obviously be in it, not elsewhere. Those parts of the application that did not depend upon the graphics package would continue to run. This level of isolation inherently provides a fail- soft capability, reducing the scope and intensity of any failure. When all the levels of software are structured in this manner, the entire system becomes more robust, secure, and flexible.
A second, even more serious problem with conventional systems is that the authority to do things (run programs, access files, etc.) is associated with an individual user name or address space. Thus, if the data base interface has the authority to access the data base, any part of the application may access the data base directly, completely bypassing the internal security mechanisms and filters of the data base manager. Similarly, all of a user's files are accessible by any program run by the user. Some systems log accesses to files in order to record programs doing things they should not, but there is no explicit mechanism to prevent misuse in the first place.
A final difficulty with conventional systems is that the rules for who can do what to whom are an integral part of the systems themselves, and are often diffused throughout the system. Examples are rules like, “any program which runs under a user name may have access to all of the files owned by that user” or “anyone who can produce the correct password may access the file” or “no one except the owner may access the file”. (Note again: the file must be owned by a user, not by a program.)
In each of these three areas - system organization, authority control, and scope of policy - conventional systems have built-in architectural barriers. It is not possible to correct them, retrofit them, or remove the deficiencies without completely redesigning these systems. The most reasonable solution to these problems is to implement a new architecture, designed to eliminate the deficiencies and take advantage of the hardware available in the computers of the 1980s. Yet such an architecture must provide considerable compatibility to protect investments in existing programs.
KeyKOS is such an architecture.