William S. Frantz
Periwinkle Computer Consulting
16345 Englewood Ave.
Los Gatos, CA USA 95032
frantz@netcom.com
(408) 356-8506
Charles R. Landau
Tandem Computers Inc.
19333 Vallco Pkwy, Loc 3-22
Cupertino, CA USA 95014
landau_charles@tandem.com
(408) 285-6148
Copyright © 1993 USENIX Association. Permission has been granted by the USENIX Association to reprint this paper. It was originally published in the Proceedings of the USENIX Symposium on Micro-Kernels and Other Kernel Architectures, September 1993.
Atomicity - "all or nothing"
Consistency - The application can ensure that the data base state does not violate application defined consistency rules.
Isolation - Transactions are logically executed serially.
Durability - Results of a completed transaction are never lost.
The checkpoint mechanism [5] is the principal way KeyKOS makes data durable or persistent. The system level checkpoint periodically saves the entire state of the system on non-volatile storage (i.e. disk). This checkpoint protects all processes, data, files, registers, etc. against the system going down (whether planned or unplanned). When KeyKOS is restarted, the state of the system at the most recent checkpoint is restored, and the all processes continue running from that state. Taking a checkpoint interrupts execution of processes for less than a second. Restart requires only the time for active processes to fault in their working sets.
A system level checkpoint is taken every few minutes, so the system must be able to commit transactions between checkpoints. To support the durability requirement of transaction processing, KeyKOS has an additional kernel-implemented operation, the Journalize Page operation. This operation saves the current contents of a virtual memory page to disk immediately so that the data will not be lost. After a restart, the data in the page will represent the data at the time the Journalize Page operation was called (or at the previous checkpoint, whichever is more recent). Using the Journalize Page operation, the KeyTXF transaction processing system can fail at any point in time without losing any committed transactions.
Fault tolerance was a major goal of the KeyKOS microkernel. In addition to the checkpoint and journaling mechanisms, the microkernel uses automatic disk mirroring to ensure that no data can be lost from a single disk failure at any time. A special mechanism, described in section 6, is used to handle disk failures that occur in the middle of writing a disk page, resulting in the page being partially written.
KeyKOS uses a time stamp which allows it to record a time with a resolution of better than a microsecond and a date covering over 100 years. [ The actual resolution depends on the hardware timing facilities available.] This time stamp is used extensively in KeyTXF. KeyTXF requires that time stamps never go backwards, and that the resolution is sufficient to generate distinct time stamps at the desired transaction rate.
KeyKOS maintains the time of the last restart and the time of the last checkpoint in a special page called the checkpoint page. This information is used by KeyTXF to detect when a restart has occurred.
The Compare and Swap operation atomically compares an "old" value with a value in memory. If they are the same, it stores a "new" value into that memory location. It returns an indication of whether a store occurred. If Compare and Swap is not available in hardware, it may be implemented in the kernel. KeyTXF assumes that it is atomic in relation to checkpoint/restart.
KeyTXF is implemented directly on the microkernel interface. KeyTXF applications can be implemented in any of the supported operating system environments including the microkernel.
Because the KeyKOS microkernel supports cheap processes, KeyTXF uses several processes for each transaction, simplifying both system and application design. These processes are objects in KeyKOS terminology. Multiple instances of the application are used to allow more than one transaction to be processed at a time. Using multiple instances allows the application programmer to program with the simplicity of single threaded logic.
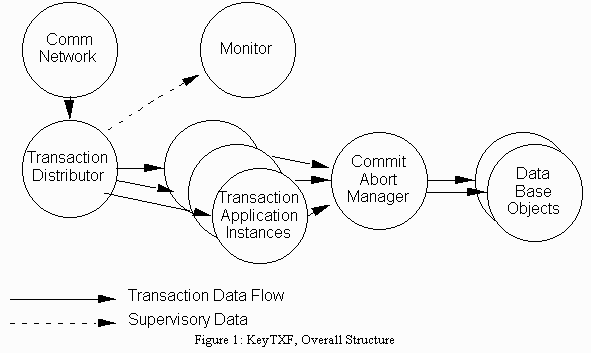
Figure 1: KeyTXF, Overall Structure
Both the Transaction Distributor and the Commit/Abort Manager dedicate an interface object to each application instance. The Transaction Distributor uses its interface object to send transactions to the application instance, monitor its status, and provide it with networking services. The Commit/Abort Manager uses its interface object, called the Commit/Abort Interface Object (CAIO) to save data to be committed as described below. KeyTXF uses these objects to serve many of the functions that the transaction ID serves in other systems.
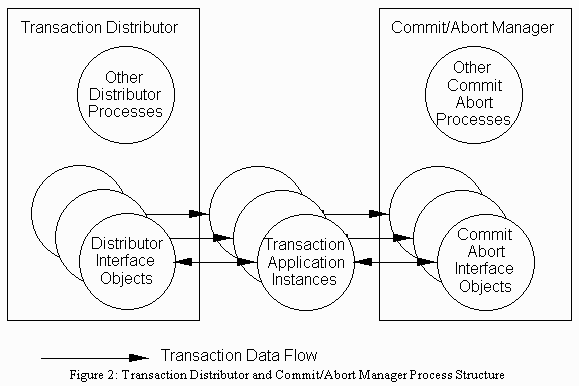
Figure 2: Transaction Distributor and Commit/Abort Manager Process Structure
In addition, the CAM is responsible detecting whether the system has restarted, and recovering from the restart. During restart recovery, the CAM reads the log and re-sends the logged changes to the database objects.
The CAM is described in detail in section 5.
The microkernel's object orientation helped us build a database out of smaller objects. We used a preexisting object type, called a record collection, which provided efficient indexed access to data. We used record collections to build a new object type, called a Multiple User Record Collection (MURC), which provides two enhancements to the basic record collection. The MURC allows multi-threaded access to data by spreading the data over multiple instances of the record collection (which is single threaded). In addition the MURC provides locking services. This construction resulted in a simple, efficient database, and took a new KeyKOS programmer two months to implement. Other data storage objects could also use wrappers to provide locking and/or interface translation.
The MURC goes through two stages of instantiation during system operation. The first stage occurs when a database is created. The MURC creates a number (specified by the caller) of record collections to hold the data. The caller has the option of arranging for these record collections to use space on different physical disk drives, to achieve parallel access. See figure 3.
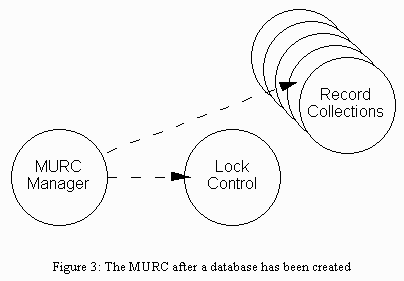
Figure 3: The MURC after a database has been created
The second stage occurs when application instances are created. Each application instance has an associated MURC Accessor (one for each database) to hold its locks and to select the record collection which holds the desired record. See figure 4. Figure 5 shows the how the CAM connects to the database objects.
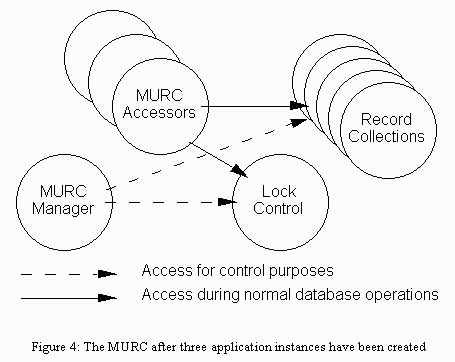
Figure 4: The MURC after three application instances have been created
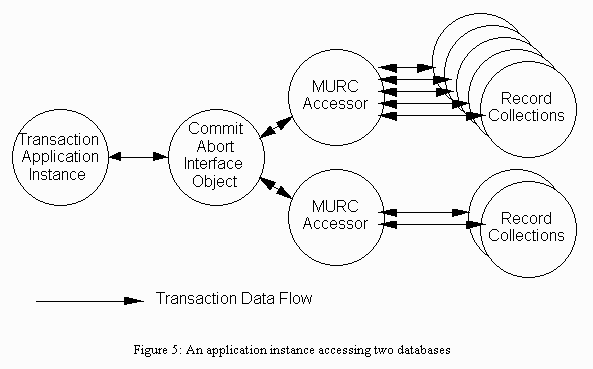
Figure 5: An application instance accessing two databases
The log is maintained in a fixed set of pages used in a circular manner. Access to the log is serialized by a lock called the log lock. The CAM maintains a global pointer to the place for the next log entry. Each page of the log has a header and a trailer, which are completely independent of the entry headers. The log page header consists of a word which is used to ensure disk write consistency (described later), and the time stamp of the last log entry that was placed in the page. The trailer consists of another word for disk write consistency assurance. The pages of the log have time stamps that are monotonically increasing, up to and including the page containing the EOF mark. As a refinement, if the EOF mark would occupy the first location in a page, it is omitted; in this case, non-monotonically increasing time stamps will mark the EOF.
Since log entries that were made before the most recent checkpoint are not needed to recover the database, the log need contain no more data than is generated in a checkpoint interval. However, there are no significant costs (other than storage costs) in having the log larger than necessary. The CAM will force a checkpoint if the log space is exhausted. This action causes all transactions to wait until the checkpoint completes, and is undesirable because it introduces a noticeable delay in transaction processing. Allocating enough space for the log avoids this cause of delay.
At the end of replay, the Commit/Abort Manager initializes the Log Pointer to point to an EOF mark in the log. See figure 6.
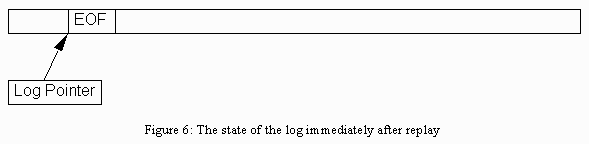
Figure 6: The state of the log immediately after replay
After transactions have been committed, the log contains some transactions that were committed before the most recent checkpoint, and some that were committed after it. See figure 7.
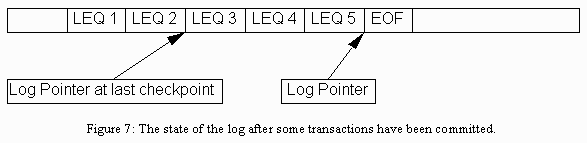
Figure 7: The state of the log after some transactions have been committed.
If the system fails at this point, the Log Pointer, the processes, and the databases (in fact, everything but the log), are backed up to their state at the last checkpoint. The log is not backed up because its pages are written out with the Journalize Page operation. The part of the log that must be replayed is the part between the log pointer and the EOF mark. See figure 8.

Figure 8: The state of the log after a restart has occurred and before replay.
Consider the case of a CAIO about to store an EOF mark in the log. The simple-minded logic would be: (1) Write the LEQ into the log, (2) store an EOF mark in the log, and (3) call Journalize Page to write the log to disk. If a checkpoint is taken during step one, and the system continues to commit transactions, we end up with a log that looks like figure 7.
If the KeyKOS restarts from that checkpoint, then the CAIO, whose state was backed up to the time of the checkpoint, completes step one, which is not a problem since copying the LEQ is an idempotent operation. But it then stores an EOF in the log, truncating the log and "uncommitting" the transactions following it in the log. To avoid this problem, the CAIO checks for restart when storing EOF in the log and at other critical points, and executes special logic if it finds that a restart has occurred.
When the CAIO completes a replay, it saves the time of last restart in a global variable. To check for restart, it compares the time of last restart in the checkpoint page with the value it saved. If they are different, then a restart has occurred.
Any time the CAIO detects that a restart has occurred, it first aborts any transaction in progress. (If the transaction was committed before the restart, then its effects on the database will be restored by replay.) The CAIO then initiates replay of the log.
Several optimizations contribute to the subtlety of the actual logic. Journalizing the pages of the log is done by independent threads for parallelism. The sequence of updating the database and journalizing the pages is arranged to maximize the probability of committing several transactions with a single journal write. And, as mentioned above, special logic is required to preserve the log when a restart occurs.
As the Commit/Abort Manager appends to the log, it needs to advance through the pages of the log. The procedure getnextlogpage is used to advance to the next page, ensuring that committed transaction entries are not nullified. The logic of getnextlogpage is:
Save the current time (called the new time stamp). If all goes well, this will be used as the new time stamp in the header of the current log page.
Check for restart. By ensuring, after storing the time stamp, that a restart has not occurred, we ensure that the time stamp stored is earlier than any need for replay. If getnextlogpage detects a restart, it does not update the time stamp in the log page header, and a replay will be started.
Copy the old time stamp in the header of the current page. Check that this time stamp is earlier than the new one. (It could be later if a checkpoint occurred after the check for restart, subsequent logging had written later entries into the page, and the system then restarted from that checkpoint.) If it is earlier, then use Compare and Swap to update the log page header time stamp passing the old time stamp as the "old" value and the new time stamp as the "new" value. This update will only succeed if the value in the page has not changed. If the value has changed, a restart has occurred.
Get the capability to the next log page and make the page addressable. If the new page header's time stamp is more recent than the last checkpoint, then the log has wrapped. Take a checkpoint to allow the log page to be reused.
Fork a log write thread to journalize the just filled page.
The complete logic to commit a transaction is:
Obtain the log lock.
Check for restart.
Write a log entry header. Writing the header destroys the EOF mark. The end of the log must be detected by time stamps until the EOF mark is written at the end of the new entry. Call getnextlogpage whenever a new page is needed to write the log entry.
Copy data from the LEQ to the log using getnextlogpage as needed.
If there is room in the current page, then write an EOF mark (a length word of zero), using the following logic to avoid truncating a log after a restart:
Store the current time stamp.
Copy the old time stamp in the log page header, and the current value of the word where we will write the EOF, into local variables (subject to checkpoint).
Check for restart. If the time stamp stored is earlier than or the same as the value found in the log page header, then a restart has occurred.
Use Compare and Swap to update the EOF mark using the value saved above as the "old" value. If the compare part of the Compare and Swap failed, a restart has occurred.
Use Compare and Swap to update the time stamp in the page header using the value saved above as the "old" value. If the compare matched then the EOF mark has been successfully stored.
Otherwise, the time stamp is different from the one saved and the system has restarted. If the time stamp we were trying to store is the same as the one now in the log page header, then the log entry being made is the last one in the log and the EOF mark just stored should remain in the log. Otherwise additional entries have been made in the log after ours and if the EOF mark is still zero, we must restore the old value (known because of the Compare and Swap). Continue with the normal restart logic.
Update the log pointer to point to the next log slot.
Release the log lock.
Perform a pre-page operation on the next few log pages to avoid a paging operation while the log lock is held.
Save the time stamp from the last log page for this log entry for use in checking for completion of the Journalize Page operations.
Process the entries in the LEQ in the order they were made. The lock entries need no action because the locks have already been obtained. For write or delete entries, call the appropriate database instance to perform the write or delete. Note whether there are any unlocked append entries, but do not perform them.
Release all database locks.
If there were any unlocked append entries, reprocess the LEQ to perform them. This logic allows an application to maintain a sequential log of transactions without that log file forcing serialization.
Ensure that the entire log entry has been journalized by checking that log writes for all log pages older than or the same age as the last page of the entry have completed. If it is necessary to schedule a write, this transaction may be delayed up to 100ms to allow other transactions to be committed by the same write. Journalizing a log page is done by forking a thread. Releasing the log lock before performing the Journalize Page operation allows one disk write of the log to commit more than one transaction if their log entries fit in the same page.
Return "transaction committed" to the caller.
Replay runs in a process of its own, but calls the CAIO's associated with each application instance to actually perform the database updates. Replay first gets the log lock to ensure all CAIO's writing into the log have completed their writes. Replay then processes the log, starting from the log pointer saved by the checkpoint, and continuing until it detects log EOF. It releases the log lock before calling the CAIO's, to ensure that they can complete their attempts to log a transaction (by aborting it) and become available to help in the replay. They regain the locks and perform the database updates. When replay is completed the application and CAIO's are destroyed and rebuilt to avoid application errors that could continue a transaction that was entered before the restart.
The KeyKOS microkernel protects against this occurrence by allocating log pages in mirrored disk storage, and completing the write operation on one page before starting it on the other. The Journalize Page operation allows pages to be placed in a special state, where the kernel will use the first and last word in the page to hold a serial number of the write count. If a page in this state is read and the serial number at the start of the page does not match the serial number at the end, then the page is known to be corrupted and the other copy is read.
This technique of failure protection can be defeated by certain algorithms in the disk controller. If for example, the disk controller caches sectors of a page and writes the first and last sectors before writing one of the middle ones, a failure may escape detection. Most SCSI disk systems do not specify whether they use such algorithms.
Other systems generate a unique Transaction ID for each transaction that is processed [3]; KeyTXF does not use Transaction ID's at all. A transaction is identified with the application instance that generates it. To distinguish transactions from different application instances, an application ID is used in the log. The application ID is reused for each transaction from the same application instance.
The Commit/Abort Interface Object serves to carry the identification of the application ID, and therefore the transaction, to the CAM. It is worthwhile to note the generality of the object-oriented microkernel paradigm here. Systems that use Transaction ID's must carry that ID in messages to entities that are involved in the transaction, such as databases and the transaction processing monitor. Often the Transaction ID is passed implicitly using an operating system level mechanism that is specific to transaction processing.
The KeyKOS microkernel was not designed specifically for transaction processing and has no such specific mechanism. But the object-oriented design of KeyTXF makes such a mechanism unnecessary. Lacking such a mechanism, the microkernel remains small and fast.
The CAIO's are the key to this design. For each application instance, the CAIO mediates the application's communication with the database objects. The interface objects are part of the CAM; they are responsible for identifying the different application instances and therefore the transactions. The application code does not need to concern itself with identifying transactions.
Mediating the application's access to the database objects is possible because of the security features of KeyKOS. An application instance has access to the CAM, but does not have any direct access to the database objects. Only the CAM has access to the database objects. Thus the CAM is in a position to control the application's access to the database objects by interposing an interface object. The KeyKOS microkernel allows this type of access control to be strictly enforced.
It is worth pointing out that an application instance is a general KeyKOS object, and as such is not restricted to a single process. It can create processes and objects, and can communicate with existing objects. The interface objects ensure that a database object is transaction protected even though the application instance may pass its capability to the CAIO on to other objects.
The superior performance resulted from the microkernel design and implementation. The microkernel's checkpoint mechanism supports the caching in virtual memory of information normally stored in disk files, while maintaining consistency and durability.