Alan C. Bomberger
A. Peri Frantz
William S. Frantz
Ann C. Hardy
Norman Hardy
Charles R. Landau
Jonathan S. Shapiro
Copyright © 1992, Jonathan S. Shapiro. All rights reserved. Permission to reproduce this document for non-commercial use is hereby granted, provided that this copyright notice is retained.
This paper first appeared in Proceedings of the USENIX Workshop on Micro-Kernels and Other Kernel Architectures, USENIX Association, April 1992. pp 95-112
KeyKOS is characterized by a small set of powerful and highly optimized primitives that allow it to achieve performance competitive with the macrokernel operating systems that it replaces. Objects are exclusively invoked through protected capabilities, supporting high levels of security and intervals between failures in excess of one year. Messages between agents may contain both capabilities and data. Checkpoints at tunable intervals provide system-wide backup, fail-over support, and system restart times typically less than 30 seconds. In addition, a journaling mechanism provides support for high-performance transaction processing. On restart, all processes are restored to their exact state at the time of checkpoint, including registers and virtual memory.
This paper describes the KeyKOS architecture, and the binary compatible UNIX implementation that it supports.
Tymnet is a registered mark of British Telecom, Inc.
UNIX is a registered mark of AT&T Bell Laboratories, Inc.
Tymshare, Inc. developed the earliest versions of KeyKOS to solve the security, data sharing, pricing, reliability, and extensibility requirements of a commercial computer service in a network environment. Development on the KeyKOS system began in 1975, and was motivated by three key requirements: accounting accuracy that exceeded any then available; 24-hour uninterrupted service; and the ability to support simultaneous, mutually suspicious time sharing customers with an unprecedented level of security. Today, KeyKOS is the only commercially available operating system that meets these requirements.
KeyKOS began supporting production applications on an IBM 4341 in January 1983. KeyKOS has run on Amdahl 470V/8, IBM 3090/200 (in uniprocessor System/370 mode), IBM 158, and NAS 8023. In 1985, Key Logic was formed to take over development of KeyKOS. In 1988, Key Logic began a rewrite of the nanokernel in C. After 10 staff months of effort a nanokernel ran on the ARIX Corporation 68020 system, and the project was set aside. The project resumed in July of 1990 on a different processor, and by October of 1990 a complete nanokernel was running on the Omron Luna/88K. The current nanokernel contains approximately 20,000 lines of C code and less than 2,000 lines of assembler code.
This paper presents the architecture and design of the KeyKOS nanokernel, and the UNIX system that runs on top of it. In the interest of a clear presentation of the KeyKOS architecture, we have omitted a description of the underlying kernel implementation.
As a consequence, the nanokernel performs no dynamic allocation of kernel storage. This has several ramifications:
The system outside the nanokernel is completely described by the contents of nodes and pages (see below), which are persistent. This state includes files, programs, program variables, instruction counters, I/O status, and any other information needed to restart the system.
In addition, the ability to recover all run-time kernel data from checkpointed state means that an interruption of power does not disrupt running programs. Typically, the system loses only the last few seconds of keyboard input. At UNIFORUM '90, Key Logic pulled the plug on our UNIX system on demand. Within 30 seconds of power restoration, the system had resumed processing, complete with all windows and state that had previously been on the display. We are aware of no other UNIX implementation with this feature today.
Like memory pages, KeyKOS applications are persistent. An application continues to execute until it is explicitly demolished. To the application, the shutdown period is visible only as an unexplained jump in the value of the real time clock, if at all. As a result, the usual issues surrounding orderly startup and shutdown do not apply to KeyKOS applications. Most operating systems implement a transient model of programs; persistence is the exception rather than the rule. A client operating system emulator may provide transient applications by dismantling its processes when they terminate.
The single-level store model allows far-reaching simplifications in the design of the KeyKOS system. Among the questions that the nanokernel does not have to answer are:
What sets KeyKOS apart from other microkernels is the total reliance on capabilities without any other mechanisms. There are no other mechanisms that add complexity to the ideas or to the implementation. Holding a key implies the authority to send messages to the entity or to pass the key to a third party. If A does not have a key for B, then A cannot communicate with B. Applications may duplicate keys that they hold, but the creation of keys is a privileged operation. The actual bits that identify the object named by a key are accessible only to the nanokernel.
Through its use of capabilities and message passing, KeyKOS programs achieve the same encapsulation advantages of object-oriented designs. Encapsulation is enforced by the operating system, and is available in any programming language. It is the complete security of this information hiding mechanism that makes it possible to support mutually suspicious users.
A fundamental concept in KeyKOS is that a program should obey the “principle of least privilege”. To that end, the design of KeyKOS gives objects no intrinsic authority, and relies totally upon their keys to convey what authority they have. Using these facilities, the system is conveniently divided into small modules, each structured so as to hold the minimal privilege sufficient for its operation.
Entities may be referred to by multiple, distinct keys. This allows an entity that communicates with multiple clients to grant different access rights to the clients. Every key has an associated 8-bit field that can be used by the recipient to distinguish between clients. When the entity hands out a key, it can set the field to a known value. Because all messages received by the entity include the 8-bit value held in the key, this mechanism can be used to partition clients into service classes or privilege levels by giving each class a different key.
It is worthwhile to contrast this approach with the ring-structured security model pioneered in Multics and propagated in the modern Intel 80x86 family. The capability model is intrinsically more secure. A ring-structured security policy is not powerful enough to allow a subsystem to depend on the services of a subsystem with lesser access rights. Ring policies intrinsically violate the principle of least privilege. In addition, ring-based security mechanisms convey categorical authority: any code running in a given layer has access to all of the data in that layer. Capability systems allow authority to be minimized to just that required to do the job at hand.
Using a capability model offers significant simplifications in the nanokernel. Among the questions that the nanokernel does not have to answer are:
The nanokernel is the only portion of the system that interprets keys. No other program has direct access to the bits contained in the keys, which prevents key forgery. In addition, the nanokernel includes code that defines the primitive system objects. These objects are sufficient to build the higher-level abstractions supported by more conventional operating systems. The nanokernel provides:
In addition to local checkpoint support, the nanokernel provides for checkpoints to magnetic tape or remote hot-standby systems. This allows a standby system to immediately pick up execution in the event of primary system failure.
A page is designated by one or more page keys. Pages honor two basic message types: read, and write. When pages are mapped into a process address space, loads and stores to locations in a page are isomorphic to read and write messages on the page key. When a message is sent to a page that is not in memory, the page is transparently faulted in from backing store so that the operation can be performed.
Applications that perform dynamic space allocation hold a key to a space bank. Space banks are used to manage disk resource allocation. The system has a master space bank that holds keys to all of the pages and nodes in the system.[1] One of the operations supported by space banks is creating subbanks, which are subbanks of the master space bank. If your department has bought the right to a megabyte of storage, it is given a key to a space bank that holds 256 page keys. Space banks are a type of domain.
Nodes are critical to the integrity of the system. The KeyKOS system vitally depends on the data integrity of node contents. As a result, all nodes are replicated in two (or more) locations on backing store. In keeping with the general policy of not performing dynamic allocation in the kernel, and because the integrity requirements for nodes are so critical, KeyKOS does not interconvert nodes and pages.
Nodes are the glue that holds segments together. KeyKOS implements segments as a tree of nodes with pages as the leaves of the tree. This facilitates efficient construction of host architecture page tables. Because nodes and pages persist, so do segments. The system does not need to checkpoint page table data structures because they are built exclusively from the information contained in segments.
KeyKOS processes can be preempted. Holding a key to a meter that provides 3 seconds of CPU time does not guarantee that the process will run for 3 contiguous seconds. In the actual KeyKOS implementation, time slicing is enforced by allowing a process to run for the minimum of its entitled time or the time slice unit. Political scheduling policies may be implemented external to the kernel.
In addition to modeling the machine architecture, domains contain 16 general key slots and several special slots. The 16 general slots hold the keys associated with the running program. When a key occupies one of the slots of a domain, we say that the program executing in that domain holds the key. One of the special slots of the domain is the address slot. The address slot holds a segment key for the segment that is acting as the address space for the program. On architectures with separate instruction and data spaces, the domain will have an address slot for each space. Each domain also holds a meter key. The meter key allows the domain to execute for the amount of time specified by the meter.
KeyKOS processes are created by building a segment that will become the program address space, obtaining a fresh domain, and inserting the segment key in the domain’s address slot. The domain is created in the waiting state, which means that it is waiting for a message. A threads paradigm can be supported by having two or more domains share a common address space segment.
Because domain initialization is such a common operation, KeyKOS provides a mechanism to generate “prepackaged” domains. A factory is an entity that constructs other domains. Every factory creates a particular type of domain. For example, the queue factory creates domains that provide queuing services. An important aspect of factories is the ability of the client to determine their trustworthiness. It is possible for a client to determine whether an object created by a factory is secure. Understanding factories is crucial to a real understanding of KeyKOS, but in the interest of brevity we have elected to treat factories as “black boxes” for the purposes of this paper. To understand the UNIX implementation it is sufficient to think of factories as a mechanism for cheaply creating domains of a given type.
Messages are composed of a parameter word (commonly interpreted as a method code), a string of up to 4096 bytes, and four keys. A domain constructs a message by specifying an integer, contiguous data from its address segment, and the keys to be sent. Only keys held by the sender can be incorporated into a message. Once constructed, the message is sent to the object named by a specified key. Sending a message is sometimes referred to as key invocation.
KeyKOS supplies three mechanisms for sending messages. The call operation creates a resume key, sends the message to the recipient, and waits for the recipient to reply using the message’s resume key. While waiting, the calling domain will not accept other messages. A variant is fork, which sends a message without waiting for a response. The resume key is most commonly invoked using a return operation, but creative use of call operations on a resume keys can achieve synchronous coroutine behavior. The return operation sends a message and leaves the sending domain available to respond to new messages. All message sends have copy semantics.
The nanokernel does not buffer messages; a message is both sent and consumed in the same instant. If necessary, invocation of a key is deferred until the recipient is ready to accept the message. Message buffering can be implemented transparently by an intervening domain if needed. The decision not to buffer messages within the nanokernel was prompted by the desire to avoid dynamic memory allocation, limit I/O overhead, keep the context switch path length short, and simplify the checkpoint operation.
A message recipient has the option to selectively ignore parts of a message. It may choose to accept the parameter word and all or part of the byte string without accepting the keys, or accept the parameter word and the keys without the data.
The KeyKOS system maintains two disk regions as checkpoint areas. When a checkpoint is taken, all processes are briefly suspended while a rapid sweep is done through system memory to locate modified pages. No disk I/O is done while processes are frozen. Once the sweep has been done, processes are resumed and all modified pages are written to the current checkpoint area. Once the checkpoint has completed, the system makes the other checkpoint area current, and begins migrating pages from the first checkpoint area back to their home locations. Checkpoint frequency is automatically tuned to guarantee that the page migration process will complete before a second checkpoint is taken. Because the migration process is incremental, a power failure during migration never leads to a corrupt system.
An implementation consequence of this approach to checkpointing is unusually efficient disk bandwidth utilization. Checkpoint, paging, and page migration I/O is optimized to take advantage of disk interleave and compensates for arm latencies to minimize seek delays. This accounts for all page writes. The aggregate result is that KeyKOS achieves much higher disk efficiency than most operating systems. If the system bus is fast enough, KeyKOS achieves disk bandwidth utilization in excess of 90% on all channels.
It is worth emphasizing that the checkpoint is not simply of files, but consists of all processes as well. If an update of a file involves two different pages and only one of the pages has been modified at the time of the checkpoint, the file will not be damaged if the system is restarted. When the system is restarted the process that was performing the update is also restarted and the second page of the file is modified as if there had been no interruption. A power outage or hardware fault does not leave the system in some confused and damaged state. The state at the last checkpoint is completely consistent and the system may be restarted from that state without concern about damaged files.
The journaling mechanism commits pages by appending them to the most recent committed checkpoint. As a result, journaling does not lead to excessive disk arm motion. A curious consequence of this implementation is that transaction performance under KeyKOS improves under load.[2] This is due to locality at two levels. As load increases, it becomes common for multiple transactions to be committed by a single page write. In addition, performing these writes to the checkpoint area frequently allows the journaling facility to batch disk I/O, minimizing seek activity. The KeyKOS transaction system significantly exceeds the performance of competing transaction facilities running on the same hardware. CICS, for example, is unable to commit multiple transactions in a single write.
Recall that a KeyKOS application has an address space, a domain, and a meter. Each of these objects holds a start key to an associated domain known as its keeper. When the process performs an illegal, unimplemented, or privileged instruction, the error is encapsulated in a message which is sent to the appropriate keeper, along with the keys necessary to transparently recover or abort the application. The keeper may terminate the offending program, supply a correct answer and allow execution to continue, or restart the offending instruction.
Each segment has an associated segment keeper. The segment keeper is a KeyKOS process that is invoked by the kernel when an invalid operation, such as an invalid reference or protection violation, is performed on a segment. Page faults are fielded exclusively by the nanokernel.
By appropriate use of a meter keeper, more sophisticated scheduling policies can be implemented. The meter keeper is invoked whenever the meter associated with a domain times out. A thread supervisor might implement a priority scheduling policy by attaching the same meter keeper to all threads, and having the meter keeper parcel out time to the individual threads according to whatever policy seemed most sensible.
The most interesting keeper for this paper is the domain keeper. The domain keeper is invoked when a trap or exception is taken. When a domain encounters an exception (system call, arithmetic fault, invalid operation, etc.) the domain stops executing and the domain keeper receives a message. The message contains the non-privileged state of the domain (its registers, instruction counter, etc.), a domain key to the domain, and a form of resume key that the keeper can use to restart the domain. When the faulting domain is restarted, it resumes at the instruction pointed to by the program counter. If necessary, the domain keeper can adjust the PC value of the faulting domain before resumption.
Our experience in implementing other systems was that breaking an application into separate function-oriented domains simplified the application enough to improve overall performance. A second goal of the KeyNIX implementation was to learn where such decomposition into separate domains would cause performance degradation. In several areas, multi-domain implementations were tried where the problem area was clearly a boundary case in order to explore the limitations of the domain paradigm.
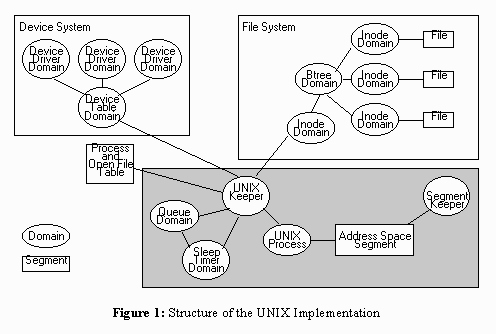
Figure 1: Structure of the UNIX Implementation
To support UNIX processes, we implemented a domain keeper, known as the UNIX Keeper. The UNIX keeper interprets the system call and either manages the call itself or directs request to other domains for servicing. The implementation includes a number of cooperating domains, is shown in Figure 1. The gray box surrounds the domains and segments that are replicated for each UNIX process.
Each of these domains in turn depends on other domains provided by the KeyKOS system. For example, a small integer allocator domain is used to allocate monotonically increasing inode numbers. To simplify the picture, domains that are not essential to understanding the structure of the UNIX implementation have been omitted.
State that must be shared between multiple UNIX keepers, including the process table and open file table, is kept in a segment shared by all UNIX Keepers. Each process has a description block (a process table entry) that describes the process’ address space, open files, and signal handling. Process table entries contain chains of child processes and pointers to the parent process table entry. Each open file has an entry in the Open File Table which keeps track of the number of processes that have the file open, the attributes of the file, and a pointer to the data structures that buffer the file data in memory.
The UNIX keeper implements UNIX process and memory management services by calling directly on the underlying KeyKOS services. The nanokernel handles virtual memory mapping and coherency directly. When a program is loaded by exec(2), the UNIX keeper builds an address space segment and copies the executable file segment into it. Manipulating the KeyKOS segment structures is simpler than the equivalent structure manipulations in UNIX, and allows the UNIX keeper to be largely platform independent. The nanokernel is responsible for the construction of mapping tables for the particular hardware platform.
By making each UNIX inode into a KeyKOS domain, the UNIX Keeper does not have to manage an inode cache or worry about doing I/O to read and write inodes. When the Keeper needs to read the status information from an inode it sends a message to the Inode object and waits for the reply. Similar arguments apply to other operations. The Keeper does not cache file or directory blocks, and does not maintain paging tables for support of virtual memory. All of these functions are handled by the nanokernel.
In the original KeyNIX implementation, directory inodes contained a key to a B-tree domain that was an underlying KeyKOS tool. An analysis of typical directory sizes led to the conclusion that it would be more space efficient to implement small directories (less than five entries) in the inode itself. As a result, directory protocol requests are implemented directly by the inode domain. If the inode does not denote a directory it fails the directory messages appropriately. A curious artifact of this approach is that directory order is alphabetical order. This is occasionally visible to end users as a change of behavior in programs that search directories without sorting them.
When opening a file, the UNIX Keeper issues a message to the file system root inode domain. This domain in turn calls on other domains, until ultimately the request is resolved to a segment key that holds the file content. Once the file has been located, the UNIX keeper maps the segment into the keeper address space and adds an entry to the open file table. The open file table is shared by all UNIX Keepers, and is used to hold dynamically changing information such as the file’s current size and last modification date.
When opening a device, the UNIX Keeper receives the major and minor device number from the appropriate inode domain. The major number is in turn handed to the device table domain, which returns a key to the domain that implements the driver. Drivers implemented in the prototype include character I/O, graphics console (supports the X Window System), the null device, sockets, kmem, and the mouse. Support for /dev/kmem is limited to forging those responses necessary to run the ps(1) command. In most cases, the device driver domain consists of the original UNIX device driver code linked with a support library that maps the UNIX driver-kernel interface onto KeyKOS key invocations.
UNIX signals are asynchronous with respect to the receiving process. As a result, the implementation of the signal mechanism is one of the more complicated and pervasive (not to say perverse) aspects of the UNIX kernel.[3]
To ensure that the UNIX Keeper is always able to receive signal notifications promptly, trivial queuing domains are required where an operation might block or complete slowly. The purpose of these domains is to queue messages to devices such as ttys and pipes that might otherwise delay the receipt of signals by the UNIX Keeper. The UNIX Keeper delivers these messages through the queue domain, and waits asynchronously for the queue domain to send a message indicating completion of the requested service. In effect, a series of fork messages are used to implement a non-blocking remote procedure call to the device domain in order to ensure that the UNIX kernel is always ready to receive another message.
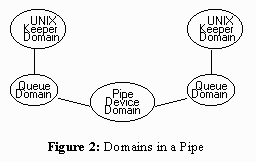
Figure 2: Domains in a Pipe
The queue insertion approach has unfortunate consequences for slow devices (with disk devices one can reasonably assume instant service and duck the issue), and severely impacted communication facilities such as pipes or sockets, as shown in Figure 2.
These mechanisms are penalized by the requirement from both sides to remain able to receive signals while proceeding with the I/O transfer. The impact is easily visible in the performance of KeyNIX pipes. A better alternative is discussed below.
The object paradigm was at the heart of the design of the KeyKOS system and, as a result, the task switch costs are very much lower than in traditional systems and several times lower than in competing microkernels such as MACH and Chorus. On the Motorola 88x00 series, a typical message send takes less than 500 cycles.[4] The low cost of task switches makes it possible to obtain better performance with much simpler software by taking an object-oriented approach to the decomposition of the system. The UNIX implementation described here takes considerable advantage of KeyKOS building blocks. The complete UNIX kernel implementation is approximately 16,000 lines of C code.
The existing prototype does not support all BSD 4.3 system calls. The major criterion for choosing what to implement and what not to implement was the need to run X-Windows, csh(1), ls(1) and similar useful utilities. If the system call is not needed to run these applications then it is not implemented. There are a number of calls that are implemented in a limited fashion, again sufficiently to run the required applications. As an example, csh(1) makes usage(2) calls but does not depend on the answers for correct behavior. Usage(2) always returns the same fixed values and is not useful as a measuring tool as a result.
To get an intuitive sense of the compatibility achieved, it may suffice to say that all of the application binaries running on KeyKOS were obtained by copying the binary file from the existing BSD 4.3 system. The X Window System, compilers, shells, file system utilities, etc. all run without change under KeyNIX.
Operation Iterations KeyNIX MACH 2.5 Ratio getpid(); 10,000 12,000/sec 30,000/sec 0.4 open();close(); 1,000 714/sec 2,777/sec 0.26 fork();exit(); 100 64/sec 10/sec 6.4 exec(); 100 151/sec 12/sec 11.6 sbrk(4096);sbrk(-4096) 100 2,564/sec 181/sec 14
I/O performance was equally mixed:
Operation KeyNIX MACH 2.5 Ratio Pipe (round trip) .588 Mbyte/sec 1.05 Mbyte/sec .56 Disk access program 4 seconds 26 seconds 6.5
As anticipated, the simplification achieved by adding domains doesn’t always lead to better performance. The cases that the KeyNIX prototype handled poorly have straightforward corrections which are discussed below.
The MACH 2.5 implementation is able to execute these system calls 2.5 times as fast as the KeyNIX system because no context switch is involved. MACH 3 uses special system call libraries to implement some of these functions in the UNIX process address space. A similar approach would be possible in KeyNIX if the system calls were implemented in dynamic libraries, as in System V Release 4, or if binary compatibility could be sacrificed. We were surprised that KeyNIX did so well on this comparison.
The current KeyNIX implementation suffers from an extremely naïve loader implementation in the UNIX keeper. When performing a fork(2), a complete copy of the process address space is made. The implementation could be improved by sharing the read-only text pages rather than copying their content. In addition, it would not be difficult to implement UNIX copy-on-write semantics as part of the segment keeper that services faults on the UNIX address space. Neither of these optimizations was performed in the prototype due to time constraints, and we would expect each to result in substantial improvements.
This result is principally due to the insertion of queue domains into both ends of the pipe, imposing considerable context switch overhead. In retrospect, we could have eliminated the queues and depended on the fact that asynchronous signal delivery timing is not guaranteed by the UNIX process model. In particular, correct UNIX programs cannot depend on the fact that interprocess signals will interrupt a system call in the receiving process. Taking advantage of this loophole would allow for a much simpler and faster implementation.
KeyNIX I/O performance is a direct result of the underlying KeyKOS I/O design. KeyKOS never writes to disk as a direct result of writing to a file. All writes to the disk are part of the paging, checkpoint, and migration system.
To determine the impact of the checkpoint process on the test, we arranged for KeyKOS to perform a checkpoint and migration in parallel. This process increases the KeyKOS time to 4.4 seconds, giving a performance ratio of 5.9 to one. To the best of our knowledge, the prototype KeyNIX system achieves the highest I/O bandwidth utilization of any UNIX system today.[6] KeyKOS’s I/O performance makes the overall performance of many applications better under KeyNIX than under a more conventional system, and appears to more than balance the prototype’s performance deficiencies.
The first approach is to build the entire directory and inode support structure for a file system into a single domain, while continuing to implement files as individual segments. This would eliminate almost all of the context switching performed in the file subsystem, and would probably outperform the MACH 2.5 implementation.
The second alternative is to implement a compatibility library that would enable us to simply compile a vnodes-compatible file system into a domain. Using this approach, the entire file system would reside in a single KeyKOS segment, and bug-for-bug compatibility is achievable. This approach is something like the File Manager tasks of CHORUS and MACH 3. In practice, supporting vnodes file systems is probably a compatibility requirement for a commercial UNIX implementation, but system reliability suffers greatly from this requirement.
Our current preference would be the first alternative, mainly to eliminate the bugs of the existing file system implementations. In addition, we feel that this approach significantly simplifies recovery in the event of a disk block failure, as it eliminates the need for a complicated file system consistency checker.
KeyKOS represents a pardigmatic shift in operating system technology. It is therefore difficult to make direct comparisons with other approaches. A pure capability architecture brings fundamentally greater discipline, control, and reliability to application construction. In the long term, we feel that this degree of reliability is necessary to realize the productivity promises of the information age.
For further information on KeyKOS:
Norman Hardy[2] Up to a point. There ain’t no such thing as a free lunch.
[3] This is also a significant problem for debugging interfaces, such as /proc(4) and ptrace(2).
[4] This time includes the context switch and copying both data and keys. The Motorola implementation is the slowest implementation to date.
[5] One round trip to access the inode domain, the second to access the directory domain.
[6] We are well aware of the significance of the I/O subsystem design in this claim, and believe that the claim would hold up when examined with other I/O subsystems and bus architectures. On the System/370, KeyKOS achieves channel utilization of better than 95% on all channels. With current SCSI technology, KeyKOS’s disk utilization is limited by the SCSI channel performance.