[ Home] [Tech Library]
5. Agents and strategiesWhen a problem needs to be solved frequently, but no single solution is right in all situations, it is desirable to permit the testing and use of many solutions. To allow this freedom, one seeks to separate mechanism and policy, designing foundations that support a wide range of policies via general-purpose mechanisms. Foundational mechanisms for ownership and trade of information and computational resources allow the choice of policy to be delegated to individual objects; these objects may in turn delegate their choices to other objects, termed agents. Even policies for such fundamental processes as processor scheduling and memory allocation can be so delegated. The following argues that agents at a higher level can accomplish adaptive automatic data structure selection, guide sophisticated code transformation techniques, provide for competition among business agents, and maintain reputation information to guide competition. 5.1. Resource allocation and initial market strategiesSystems programming problems such as garbage collection and processor scheduling have traditionally been addressed in the computational foundations, casting the architect in the role of omniscient central planner. In this approach, the architect imposes a single, system-wide solution based on global aggregate statistics, precluding local choice. In the market approach, however, these problems can be recast in terms of local negotiation among objects. Solutions in this framework also provide objects with price information, allowing them to make profitable use of the resulting flexibility. This enables programmers to provide objects with specialized resource allocation strategies, but it need not force programmers to attend to this. Objects can delegate these strategic issues to business agents, and a programming environment can provide default agents when the programmer does not specify otherwise. The companion paper "Incentive Engineering for Computational Resource Management" [III] describes and analyzes initial market strategies which, if followed by a set of business agents, result in distributed algorithms for allocation of processor time, memory space, and communication channels. Initial market strategies (whether these or others) will play a key role in establishing agoric systems: from a traditional programming perspective, they will provide initial policies for garbage collection and processor scheduling; from a market perspective, they will help provide initial resource prices and thus an environment in which more sophisticated entities can begin to operate. Thus, they will help bridge the gap between current practice and computational markets. As markets evolve, the scaffolding provided by initial market strategies may be largely or entirely replaced by other structures. The initial strategies for processor scheduling are based on an auction in which bids can be automatically escalated to ensure that they are eventually accepted. The initial strategies for memory allocation and garbage collection are based on rent payment, with objects paying retainer fees to objects they wish to retain in memory; objects that are unwanted and hence unable to pay rent are eventually evicted, deallocating their memory space. These approaches raise a variety of issues (including the threat of strategic instabilities stemming from public goods problems) that are addressed in our companion paper. Together, these strategies provide a proof of concept (or at least strong evidence of concept) for the notion of decentralized allocation of computational resources. Initial market strategies will provide a programmable system that generates price information, enabling a wide range of choices to be made on economic grounds. For example, processor and memory prices can guide decisions regarding the use of memory to cache recomputable results. Given a rule for estimating the future rate of requests for a result, one should cache the result whenever the cost of storage for the result is less than the rate of requests times the cost of recomputing the result (neglecting a correction for the overhead of caching and caching-decisions). As demand for memory in a system rises, the memory price will rise, and these rules should free the less valuable parts of caches. If the processing price rises, caches should grow. Thus, prices favor tradeoffs through trade. 5.2. Business location decisionsPrice information can guide a variety of other choices. Many of these resemble business location decisions. Main "core" memory is a high-performance resource in short supply. Disk is a lower performance resource in more plentiful supply. In an agoric system, core memory will typically be a high-rent (business) district, while disk will typically be a low-rent (residential) district. Commuting from one to the other will take time and cost money. An object that stays in core will pay higher rent, but can provide faster service. To the degree that this is of value, the object can charge more; if increased income more than offsets the higher rent, the object will profit by staying in core. Treating choice of storage medium as a business location problem takes account of considerations-such as the relative value of prompt service-that traditional virtual memory algorithms do not express. Small objects would have an incentive to "car-pool" in disk-page sized "vehicles". But given the issues described in Section 3.5, a typical object buying resources on the market may occupy many pages. Instead of deciding whether it should be completely in or out of core, such an object might decide how many of its pages should be part of an in-core working set, perhaps relying on a traditional algorithm [32] to dynamically select the in-core pages. The variety of types of memory also suggests a need for more flexibility than the traditional two-level approach provides. The many kinds of memory differ in many ways: consider fast RAM cache, write-once optical disk, and tape archived in multiple vaults. Memory systems differ with respect to:
Tradeoffs will change as technology changes. To be portable and viable across these changes, programs must be able to adapt. Much has been written about the need to migrate objects in a distributed system in order to improve locality of reference [30,33,34]. Again, this resembles the problem of choosing a business location. Machines linked by networks resemble cities linked by highways. Different locations have different levels of demand, different business costs, and different travel and communications costs. Various traditional approaches correspond to:
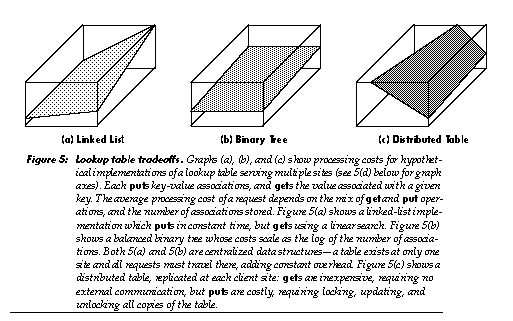
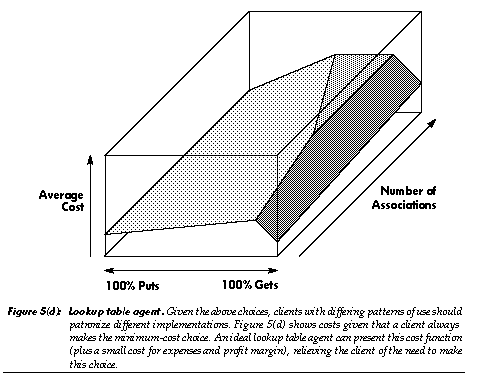
If limited to any one of these methods, human societies would suffer terrible inefficien- cies. One expects the same for large, diverse software systems. If a system's mechanisms support a range of policies, different objects can select different approaches. The notion of location in a space is still rare in object-oriented programming (for an exception see [41]). All memory in an ideal von Neumann computer is effectively equidistant, and many real computers approximate this ideal, but in a widely distributed system, differing distances are of real importance. When objects are given an account of the costs of communicating and commuting, they gain a useful notion of distance for making economic decisions. 5.3. Business agentsIn a market containing sophisticated, potentially malicious objects, how can simple objects hope to negotiate, compete, and survive? One answer would be to shelter simple, mutually-trusting objects within large, sophisticated objects, building the latter out of the former. This model, however, would preclude turning loose small objects as service-providers on the open market. Other means are required for giving small objects the market sophistication they need. Just as delegation of tasks to other objects can enable a small, simple object to offer sophisticated services, so delegation can enable it to engage in sophisticated market behavior. In this work's terminology, an object can delegate competence-domain actions to a subcontractor; this corresponds to the normal practice of hierarchical decomposition, which originated with the subroutine. An object can likewise delegate performance-domain actions to an agent; this seems likely to be a normal practice in agoric systems. Simple objects then can make their way in a complex world by being born with service relationships to sophisticated agents (which themselves can be composed of simple objects, born with. . .). Initially, human decisions will establish these relationships; later, specialized agent-providing agents can establish them as part of the process of creating new economic objects. The initial market strategies mentioned in Section 5.1 could be provided by simple agents. One might object that a simple object and its collection of agents together constitute a complex object. But these objects, though complex in the performance domain, can remain extremely simple in the competence domain. Further, large agents need not burden a simple object with enormous costs; in general a large number of objects would share the agents and their overhead. The object-and-agent approach thus can enable entities of simple competence to compete in the open market. 5.3.1. Data-type agentsIn object-oriented programming, one can supply multiple implementations of an abstract data type, all providing the same service through the same protocol, but offering different performance tradeoffs [28]. An example is the lookup table, which may be implemented as an array, linked list, hash table, B-tree, associative memory, or as any of several other devices or data structures. In an object-oriented system, code which uses such an abstract data type is itself generally abstract, being independent of how the data type is implemented; this provides valuable flexibility. In contrast, code which requests an instance of such an abstract data type is usually less abstract, referring directly to a class which provides a particular implementation of that type. The resulting code embodies decisions regarding implementation tradeoffs in a relatively scattered, frozen form. In a market, agents can unfreeze these decisions: instantiation requests can be sent to a data-type agent, which then provides a suitable subcontractor. In human markets, someone seeking a house can consult a real-estate agent. The real-estate agent specializes in knowing what is available, what tradeoffs are important, and what to ask clients regarding those tradeoffs. Similarly, a lookup table agent could know what lookup table implementations are available, what tradeoffs they embody, and (implicitly, through its protocol) what to ask clients regarding those tradeoffs (e.g., a request might indicate "I will often be randomly indexing into the table"). The agent could also "ask questions" by providing a trial lookup table that gathers usage statistics: once a pattern becomes clear, the agent can transparently switch to a more appropriate implementation. Long term, sporadic sampling of usage patterns can provide a low-overhead mechanism for alerting the agent to needed changes in implementation. An agent can do more. For example, the relative price of memory and processor time may vary with the time of day or with the state of technology; depending on the cost of different implementations and the cost of switching among them, a change may be profitable. Likewise, the table-user may desire faster responses; again, a change may be profitable. If a newly-invented lookup table implementation is superior for some uses, it could be advertised (by its advertising agent) to prominent lookup table agents. "Advertising" could include paying these agents to test its performance under different patterns of use, enabling them to determine which of their clients could benefit from switching to it. The new table would soon be used by programs that were coded without knowledge of it, and which started running prior to its creation. Unrelated agents can interact synergistically. Consider the case of a lookup table with distinct read and write ports and distributed users. As long as there are writers, this lookup table chooses to exist on only one machine (in order to preserve serializable semantics without the complexity of distributed updates). This implementation imposes substantial delays and communication costs on the readers: if all objects dropped access to its write port, the lookup table could transmit static copies of itself to all readers, lowering these costs. The table can represent this cost by charging an artificially high retainer fee for the write port, giving users an incentive to drop this capability and permit a shift to the less expensive implementation. This illustrates how local economic decisions can encourage appropriate performance tradeoffs involving such distinct aspects of the system as garbage collection, network traffic, and representation of data structures.
Given sufficiently powerful partial-evaluation agents [42], a data-type agent could offer to extend an object with a new protocol. For example, the user of a lookup table might frequently look up the values of the first N entries following a particular key. Rather than doing so by running a procedure using the existing protocol, it could offer to pay for partially evaluating the procedure with respect to the lookup table, and add a lookup-next-N request to the table's protocol. This would typically make servicing such requests more efficient; a portion of the resulting savings could paid as dividends to the object that invested in the partial evaluation. 5.3.2. ManagersDifferent agents of the same type will have different reputations and pricing structures, and they will compete with each other. An object must select which of these agents to employ. Just as an object may employ a lookup table agent to decide which lookup table to employ, so an object may employ an agent-selection agent to decide which agent to employ. Agent-selection agents are also in competition with each other, but this need not lead to an infinite regress: for example, an object can be born with a fixed agent-selection agent. The system as a whole remains flexible, since different objects (or versions of a single object) will use different agent-selection agents. Those using poor ones will tend to be eliminated by competition. A generalization of the notion of an agent-selection agent is that of a manager. In addition to the functions already outlined, a manager can set prices, select subcontractors, and negotiate contracts. To select good agents and subcontractors, manager-agents will need to judge reputations. 5.3.3. ReputationsA reputation system may be termed positive if it is based on seeking objects expected to provide good service, and negative if it is based on avoiding those expected to provide bad service. Negative reputation systems fail if effective pseudonyms are cheaply available; positive reputation systems, however, require only that one entity cannot claim the identity of another, a condition met by the identity properties of actors [4,43] and public key systems [29]. Accordingly, computational markets are expected to rely on positive reputation systems. It would seem that new objects could not acquire positive reputations ("Sorry, you can't get the job unless you show you've done it before."), but they need not have given good service to make one expect good service. For example, a new object can give reason to expect good service-thereby establishing a positive reputation-by posting a cash bond guaranteeing good performance. (This requires, of course, that both parties to the contract trust some third parties to hold the bond and to judge performance.) Despite the idea that software entities cannot make commitments [44], contracts with enforceable penalty clauses provide a way for them to do so. The demand for reputation information will provide a market for reputation services, analogous to credit rating agencies, investment newsletters, Underwriters Laboratories, the Better Business Bureau, and Consumer Reports. When the correctness and quality of the service can be judged, it seems that an effective reputation service could work as follows. A reputation server approaches a service provider, offering money for service. (The server funds these purchases by selling information about the results.) The reputation agent has an incentive to appear to be a regular customer (to get an accurate sample), and regular customers have an incentive to appear to be reputation agents (to get high quality service). A restaurant reviewer has been quoted as saying "If someone claims to be me, he's not!" [45]. Given unforgeable identities, the best either can do is maintain anonymity. Service providers then have an incentive to provide consistently good service, since their reputation might be at stake at any time. This scenario generalizes to tests of reputation services themselves. 5.3.4. CompilationTradeoffs in compilation can often be cast in economic terms. For example, the best choice in a time-space tradeoff will depend on processor and memory costs, and on the value of a prompt result. Another tradeoff is between computation invested in transforming code versus that spent in running the code; this is particularly important in guiding the often computation-intensive task of partial evaluation. Investment in code transformation is much like other investments in an economy: it involves estimates of future demand, and hence cannot be made by a simple, general algorithm. In a computational market, compilation speculators can estimate demand, invest in program transformations, and share in the resulting savings. Some will overspend and lose investment capital; others will spend in better-adapted ways. Overall, resources will flow toward investors following rules that are well-adapted to usage patterns in the system, thereby allocating resources more effectively. This is an example of the subtlety of evolutionary adaptation: nowhere need these patterns be explicitly represented. Current programming practice typically sacrifices a measure of structural simplicity and modularity for the sake of efficiency. Some recent compilation technologies [42,46] can make radical, non-local transformations that change not only performance, but complexity measure. Use of such technology could free programmers to concentrate on abstraction and semantics, allowing the structure of the code to more directly express the structure of the problem. This can reduce the tension between modularity and efficiency. As we later argue, computational markets will encourage the creation of reusable, high-quality modules adapted for composition into larger objects. The resulting composite objects will typically have components paying dividends to different investors, however, imposing internal accounting overhead. Again, there is a tension with efficiency, and again it can be reduced by means of compilation technology. Much compilation involves (invisibly) "vio- lating" internal boundaries-compiling well-separated components into a complex, non-modular piece of code. In an agoric system, a compilation-agent can do the same, while also analyzing and compiling out the overhead of run-time accounting. A Pareto-preferred compiler is one which performs this transformation so as to guarantee that some component will be better off and none will be worse off. This can be achieved even if the resulting division of income only approximates the original proportions, since the total savings from compilation will result in a greater total income to divide. The expectation of Pareto-preferred results is enough to induce objects to submit to compilation; since multiple results can meet this condition, however, room will remain for negotiation. 5.4. The scandal of idle timeCurrent resource allocation policies leave much to be desired. One sign of this is that most computing resources-including CPUs, disk heads, local area networks, and much more-sit idle most of the time. But such resources have obvious uses, including improving their own efficiency during later use. For example, heavily-used programs can be recompiled through optimizing compilers or partial evaluators; pages on disk can be rearranged to keep files contiguous; objects can be rearranged according to referencing structure to minimize paging [47], and so forth. In a computational market, a set of unused resources would typically have a zero or near-zero price of use, reflecting only the cost of whatever power consumption or maintenance could be saved by genuine idleness or complete shutdown. Almost any use, however trivial, would then be profitable. In practice, contention for use would bid up prices until they reflected the marginal value of use [5]. Idle time is a blatant sign of wasteful resource allocation policies; one suspects that it is just the tip of a very large iceberg. Terry Stanley [48] has suggested a technique called "post-facto simulation" as a use of idle (or inexpensive) time. It enables a set of objects to avoid the overhead of fine-grained accounting while gaining many of its advantages. While doing real work, they do no accounting and make no attempt to adapt to internal price information; instead, they just gather statistics (at low overhead) to characterize the computation. Later, when processing is cheap and response time demands are absent (i.e., at "night"), they simulate the computation (based on the statistics), but with fine-grained accounting turned on. To simulate the day-time situation, they do not charge for the overhead of this accounting, and proceed using simulated "day" prices. The resulting decisions (regarding choice of data structures, use of partial evaluation, etc.) should improve performance during future "days". This is analogous to giving your best real-time response during a meeting, then reviewing it slowly afterward: by considering what you should have done, you improve your future performance. |
||
|
Last updated: 21 June 2001 |
[ Home] [Tech Library]